Использование контекста отслеживает, какая часть контекстного окна Claude потребляется во время разговора. Контекстное окно — это общий объем информации (ваши сообщения, ответы ИИ, код, файлы и системные инструкции), который отправляется поставщику моделей с каждым сообщением. Сам Claude не хранит ничего локально — весь контекст управляется на стороне сервера, что означает, что основное влияние размера контекста — на стоимость и скорость ответа.
Как растёт контекст
Самое важное, что нужно понимать о контексте — это то, что он растёт экспоненциально, а не линейно. Каждый раз, когда вы отправляете новое сообщение, поставщик модели получает всю историю разговора — не только ваше новое сообщение, но все предыдущие сообщения вместе. Например, отправка вашего 100-го сообщения означает, что поставщик обрабатывает все 100 сообщений одновременно.

Это имеет два практических последствия:
- Стоимость растёт экспоненциально — каждое дополнительное сообщение делает каждое последующее сообщение более дорогим, поскольку всё предыдущее содержимое повторно отправляется каждый раз.
- Внимание ухудшается — чем больше контекст, тем меньше внимания модель уделяет каждой его части. Это означает, что модель может выглядеть так, будто “забывает” то, что вы говорили ранее, или упускает детали в ваших инструкциях, фактически становясь глупее по мере роста разговора.
По этим причинам лучше избегать ненужно длинных чатов. Начинайте новые задачи в свежих чатах, а не сваливайте всё в один разговор.
Метрики токенов
Каждое сообщение в разговоре вносит токены в контекст. Ключевые метрики:

- Входные токены — токены в подсказке, отправленной в API (ваше сообщение плюс любой код, файлы или контекст)
- Токены чтения кэша — токены, поданные из кэша подсказок (повторно использованные с предыдущих шагов, намного дешевле, чем свежий ввод)
- Выходные токены — токены, сгенерированные в ответе ИИ
- Токены контекста — общий контекст, потребляемый на сообщение:
cacheReadTokens + inputTokens - Лимит контекста — максимальный размер контекстного окна, определяется на стороне сервера поставщиком модели. Переменная окружения
MODEL_CONTEXT_LENGTHуправляет только тем, что отображается в панели прогресса и графиках — установите её в соответствии с фактическим лимитом вашей модели для точных показаний - Процент использования — какая часть контекстного окна была использована:
(totalUsed / contextLimit) × 100
Отслеживание стоимости
Pastukhov Code рассчитывает и отображает стоимость на трёх уровнях:
- На сообщение — каждый ответ ИИ показывает свою стоимость в метаданных сообщения (видно, когда отображаются токены сообщения). Стоимость рассчитывается из фактического количества токенов этого сообщения с использованием цен активного окружения.
- На чат — бейдж статистики чата вверху просмотра чата показывает общую стоимость текущего разговора. Наведите на него, чтобы увидеть разбивку количества сообщений, стоимости, токенов в секунду и деталей токенов (кэш, ввод, вывод).
- Недавняя статистика (заголовок) — бейдж статистики в заголовке страницы показывает агрегированную стоимость по всем чатам в настраиваемом временном диапазоне. Он отображает общее количество подсказок, общую стоимость и среднее количество токенов в секунду. Нажмите на него, чтобы изменить временной диапазон (сегодня, последние 7 дней, этот месяц и т.д.) или открыть полную страницу аналитики.


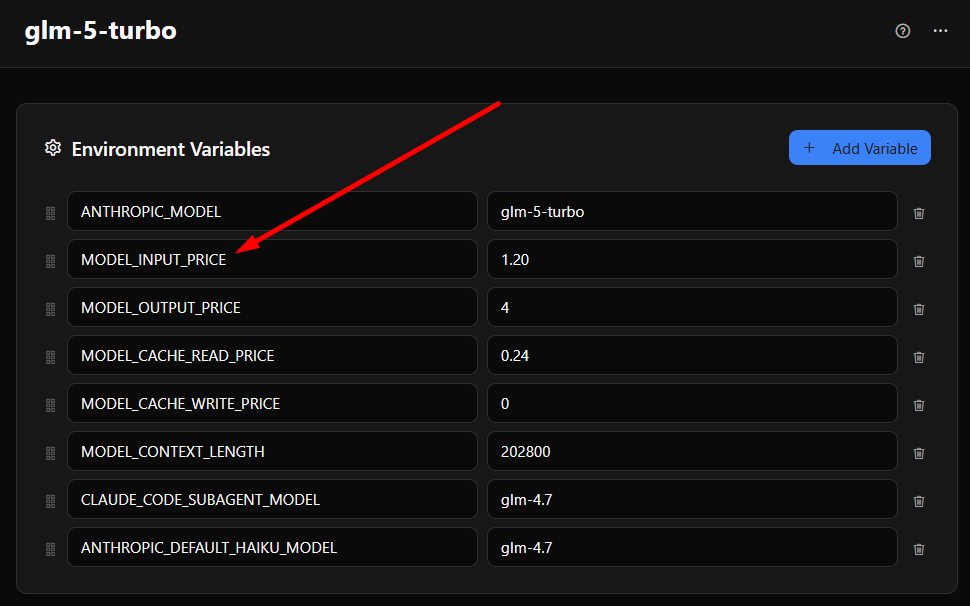
Стоимость рассчитывается с использованием четырёх ценовых переменных из активного окружения: MODEL_INPUT_PRICE, MODEL_OUTPUT_PRICE, MODEL_CACHE_READ_PRICE и MODEL_CACHE_WRITE_PRICE — всё в USD за миллион токенов. Если не установлены, используются эти значения по умолчанию:
MODEL_INPUT_PRICE— $0.60MODEL_OUTPUT_PRICE— $2.20MODEL_CACHE_READ_PRICE— $0.11MODEL_CACHE_WRITE_PRICE— $0
Эти значения по умолчанию основаны на типичном ценообразовании китайских моделей (например, GLM 4.7), а не на прейскурантах Anthropic. Если вы используете Anthropic Claude или другого поставщика, эти числа не совпадут. Вы можете установить специфику для модели ценообразование на окружение на странице Окружения — окружения иерархичны, поэтому вы можете определить общие переменные, такие как конечная точка API и ключ доступа, один раз в родительском окружении, а затем установить ценообразование для каждой модели в дочерних окружениях без их повторения. Порядок разрешения: переменные окружения → системная конфигурация → жестко закодированные значения по умолчанию.
Помните, что эти расчёты показывают, сколько запросы стоили бы по тарифам оплаты за токен API. На практике большинство пользователей подписываются на планы кодирования (Anthropic Max, GitHub Copilot и т.д.), которые в 10–30 раз дешевле. Помимо этого, реальное ценообразование гораздо сложнее, чем простая ставка за миллион токенов — поставщики могут применять разное ценообразование в зависимости от времени суток, объёма использования, размера контекста и различных скидок или штрафов. По этой причине цифры стоимости в Pastukhov Code — это лишь приблизительные оценки, полезные для сравнения относительного веса запросов и выявления необычно дорогих чатов. Страница биллинга или учётной записи вашего поставщика — единственный источник истины — проверяйте её регулярно.
Диалог графика контекста
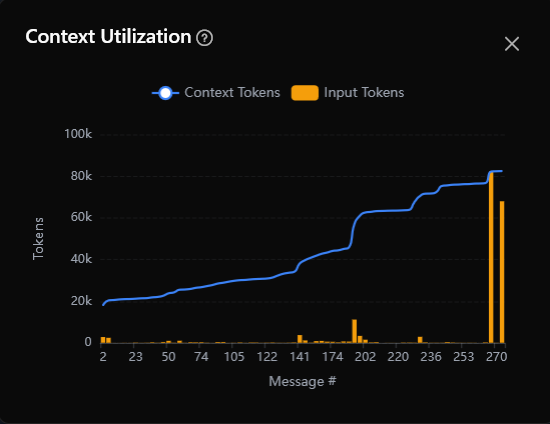
График использования контекста визуализирует использование токенов по всему разговору. Откройте его, щёлкнув на индикатор контекста в заголовке чата. График показывает два ряда данных:
- Токены контекста (синяя линия) — общий контекст, потребляемый на сообщение, показанный как сглаженная линия. Это объединяет кэшированные токены и токены свежего ввода.
- Входные токены (оранжевые полосы) — токены свежего ввода на сообщение, показанные как вертикальные полосы. Они представляют токены, не поданные из кэша.
Ось X представляет номера сообщений (1, 2, 3…) и ось Y показывает количество токенов. Значения выше 1000 отображаются в сокращённой форме (например, “50k”). Сообщения с нулевыми токенами контекста отфильтровываются из графика.
Чтение графика: растущая синяя линия означает, что ИИ потребляет больше контекста с течением времени — обычно потому, что каждое сообщение включает предыдущие сообщения плюс растущую историю разговора. Оранжевые полосы показывают, где используются свежие (некэшированные) токены, что указывает на добавление нового содержимого, а не на повторное использование.
Лимит контекста
Фактический лимит контекста определяется на стороне сервера поставщиком модели и не может быть изменён с вашей стороны. Переменная окружения MODEL_CONTEXT_LENGTH управляет только отображением — панель прогресса и графики в Pastukhov Code. Установите её в соответствии с фактическим размером контекстного окна вашей модели, чтобы процент и график отражали реальность. Если не установлена, по умолчанию используется 200,000 токенов.
Общие лимиты контекста по моделям:
- Claude Opus 4.7 / Sonnet 4.6 — 200,000 токенов
- Claude Haiku 4.5 — 200,000 токенов
- Сторонние модели — varies; установите
MODEL_CONTEXT_LENGTHв соответствии с фактическим лимитом поставщика
При переключении окружений отображение автоматически обновляется на основе значения MODEL_CONTEXT_LENGTH нового окружения.
Управление использованием контекста
Вот стратегии для контроля использования контекста:
- Начинайте новые чаты для новых тем — каждый чат начинается с чистого контекстного окна. Вместо одного длинного разговора, охватывающего несколько тем, начинайте новый чат, когда вы меняете фокус. Это самая эффективная стратегия.
- Мониторьте график — периодически проверяйте график контекста. Если вы видите, что использование круто растёт, подумайте о завершении текущей задачи и начале нового чата.
Авто-уплотнение
Когда контекст достигает около 70% лимита, Claude Code автоматически уплотняет его. Уплотнение заменяет полную историю разговора коротким сводком, сгенерированным моделью, освобождая место для новых сообщений.
Хотя уплотнение позволяет продолжить разговор, оно имеет значительные недостатки:
- Потеря информации — сводок — это потерянная абстракция полной истории. нюансы, конкретные инструкции и контекстные детали сглаживаются или полностью опускаются.
- Вводящие в заблуждение сводные — модель может неправильно суммировать ваше намерение или инструкции, и последующие ответы будут основаны на этом искажённом понимании, а не на том, что вы на самом деле сказали.
- Видимое прерывание — вы заметите события уплотнения, когда модель внезапно пытается заново понять, что вы делаете с нуля, или задаёт вопросы о вещах, которые уже обсуждались.
Когда вы видите, что происходит уплотнение, лучший курс действий — начать свежий чат. Модель может заново обнаружить контекст проекта из файлов, CLAUDE.md и памяти гораздо точнее, чем любой сводок может предоставить. Свежий старт с чистым контекстом почти всегда лучше, чем продолжение после уплотнения.